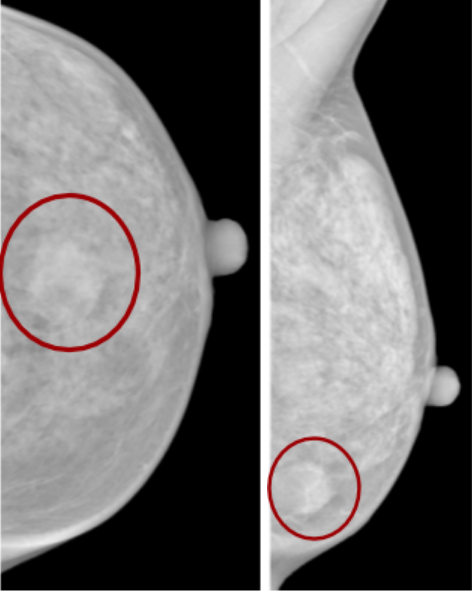
“A lesão 1 no QIE da mama esquerda corresponde a um nódulo redondo com 21 mm, margens bem circunscritas, sem agrupamento de microcalcificações associado.”
Figure 1. Different modalities may hold complementary information.
Introduction:
In many areas where information related to a certain entity is available from more than one source (e.g. visual, audio or textual information) it may be desirable to use multiple sources to find the closest match. Put in other words, we may desire an application where queries are from one domain (text) and retrieved objects are from another domain (audio). An everyday example of this is music search; we can perform music search on a database by using a “microphone-captured song snippet” (audio), or alternatively use “part of the song lyrics” (text). Both queries should return the (same) music we are looking for.
The same applies to breast cancer screening in which information is derived from images but also medical reports.
This work aims to use a set of annotated medical exams containing mammograms, an expert report and other relevant meta-information to develop models that can perform: cross-modal, uni-modal and multi-modal classification systems for Computer-Aided-Diagnosis (CAD) for breast cancer. These can include: 1) automatic medical report generation, 2) diagnosed findings localization on the mammogram, and others. Ultimately, this work contributes to improve state-of-the-art in CAD for mammography. The work is to be developed at INESCTEC, where research in this area is conducted daily.
This is an ambitious thesis project in the sense that it includes three areas of research:
- Computer-Aided-Diagnosis in medical imaging (applied to breast cancer screening),
- Image classification using state-of-the-art image classification architectures, and
- Natural language processing (NLP) applied to medical report classification/understanding.
Tasks (1st semester):
- Review the state-of-the-art in Computer-Aided-Diagnosis for breast cancer screening, image classification and NLP;
- Become familiarized with the research group's previous work;
- Become acquainted with natural image classification, NLP and mammography data;
- Formulate brave new ideas for cross-modal, multi-modal and uni-modal CAD systems for breast cancer diagnosis;
- Write monograph.
- Implementation of the new strategies mentioned above;
- Quantitatively evaluate the performance of these strategies, and perform comparisons with baseline strategy;
- Assess generalization ability of the strategies proposed; i.e. other available datasets, other tasks related to breast cancer diagnosis (e.g. localization, shape, stage, etc);
- Write the dissertation.
Advantages:
- Data is available from day 1 - already collected;
- Strong Support - this is an active area of research from the group;
- Encoragement to publish - important if you are planning on pursuing a PhD;
- Eligibility to CTM's Best Master Thesis 2021 Award;
Important skills (need to be learned by the 1st semester):
- Programming (python)
- Deep Learning
- Computer Vision
- Natural Language Processing
- Computer-Aided Diagnosis
[1] - Gao H, Aiello Bowles EJ, Carrell D, Buist DS. Using natural language processing to extract mammographic findings. J Biomed Inform. 2015;54:77-84. https://doi.org/10.1016/j.jbi.2015.01.010